


Back to resources
Defining Identities, Accounts, and the Challenge of Privilege Sprawl
August 2024 / 5 min. read /

Identity and access management (IAM) has always been crucial for maintaining security within organizations. Traditionally, IAM and other identity-focused solutions prioritize managing these identities and permissions within on-premises environments.
However, the rapid adoption of cloud technologies has necessitated a shift towards more dynamic and scalable solutions. This blog post is one of the first in exploring the evolving landscape of securing and protecting permissions in the cloud, and how traditional solutions must adapt to meet new challenges.
What is an Identity?
The first step in understanding how access security has changed is by defining an identity.
In the context of identity and access management, an identity is a way to refer to the human or end-user that needs access to the system as a unique collection of attributes. For a person, these attributes could include things such as employment status in an organization (full-time vs contractor), location, team membership, department, and job title.
These identity attributes are usually used to define the scope of a user’s roles and permissions within a system. For example, a full-time marketing employee would have access to different resources than a contractor in the IT department.
Many Identities, Many, Many (Many) Accounts
The challenge in managing all these accounts and permissions arises when it comes to managing different levels of permissions. For certain applications, the traditional identity and account relationship is flat. In these instances, there may only be a small number of account types such as a regular user and an administrator.
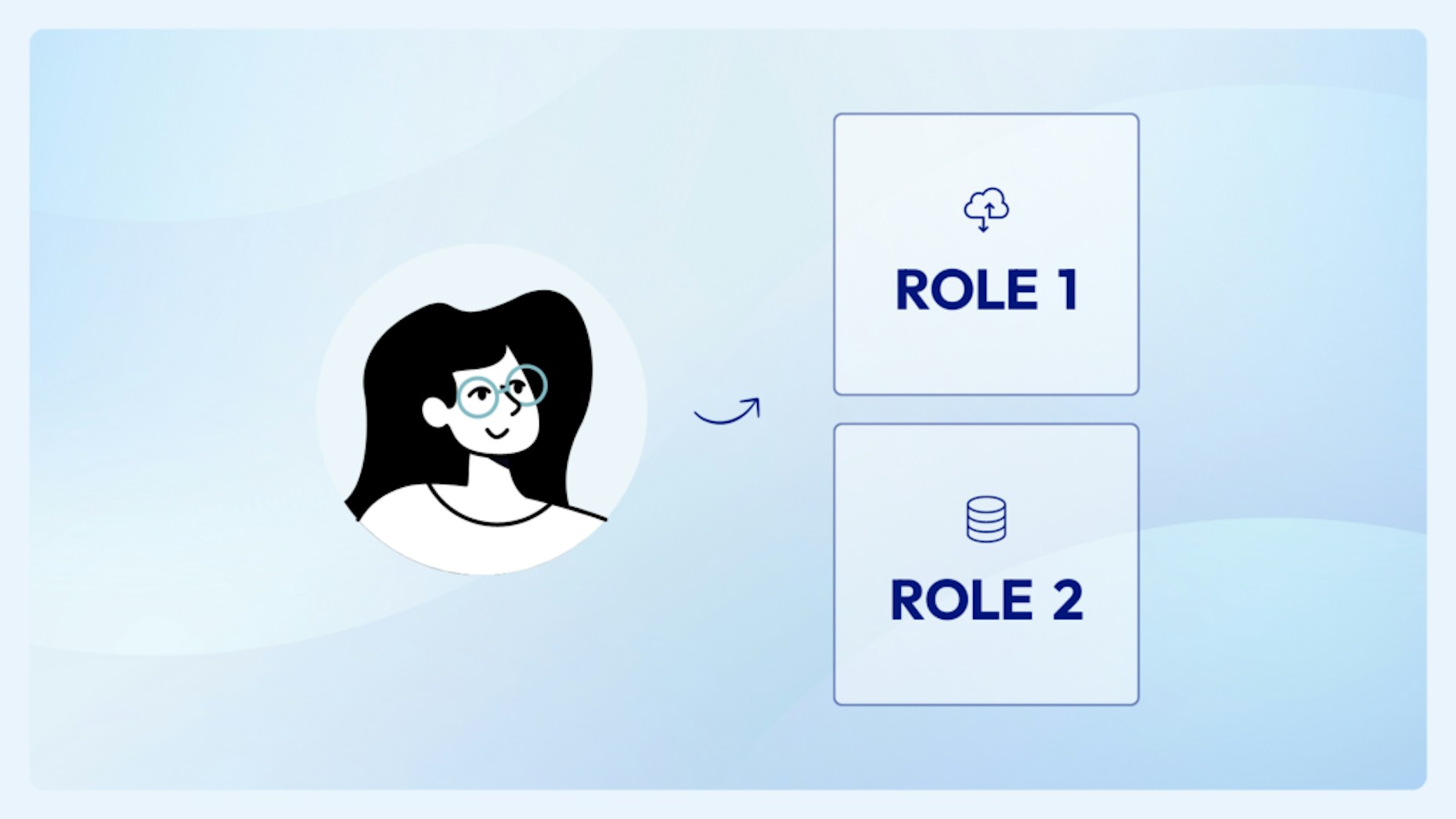
But what happens when someone needs specific, sometimes privileged access for a task that they don’t normally have to do? Most software applications have the concept of roles. Roles are collections of specific permissions that make management easier. Accounts are assigned roles which then gives them access to those permissions. Typically, a user would submit a request for access, go through an approval process, and then have their account assigned the proper role containing the needed permissions.
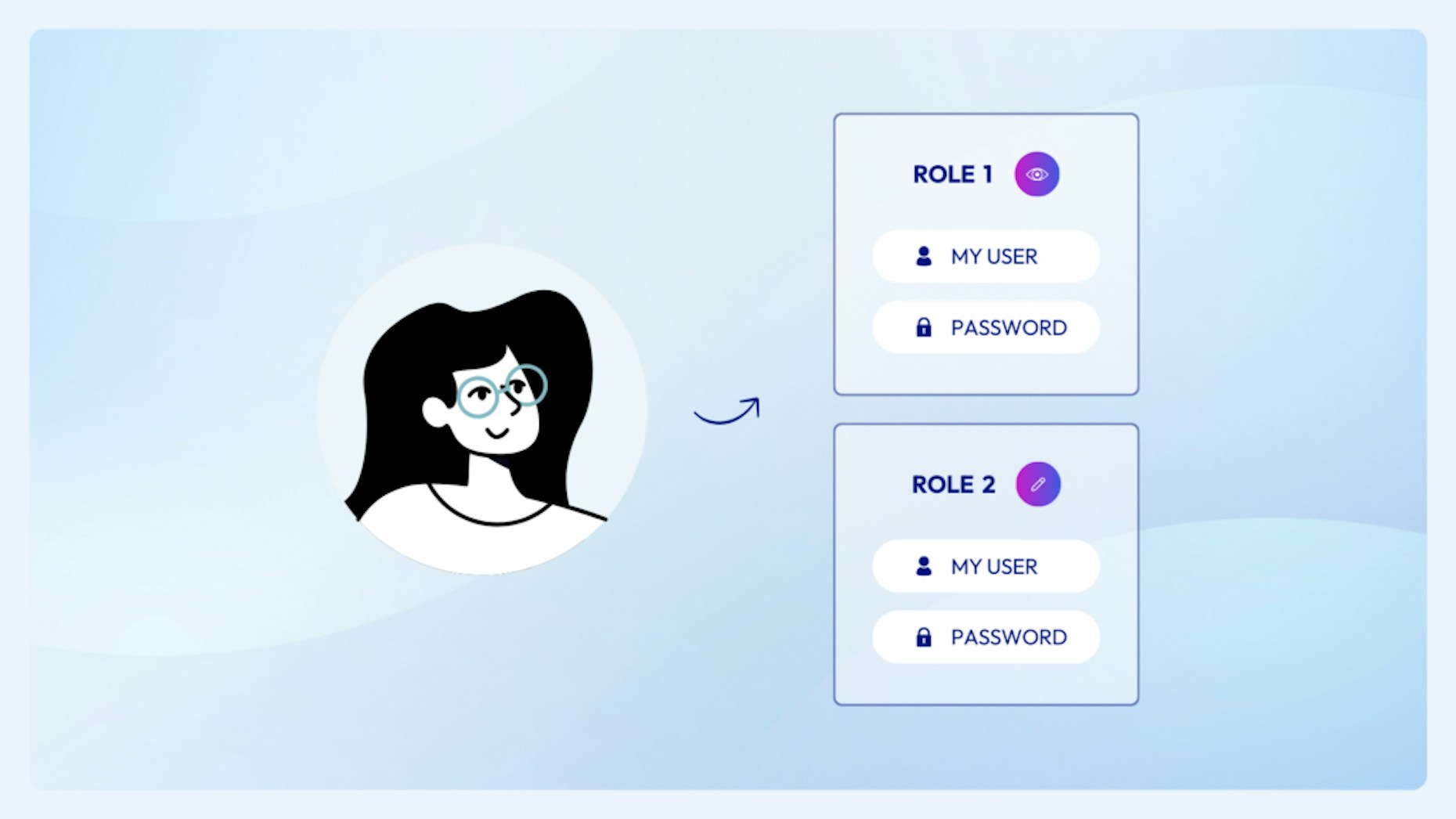
Role management can become a challenge—especially as the number of accounts and roles in a system grows. The same permission can exist in multiple roles. Any account can be assigned any combination of roles. This can make it very difficult to understand the total scope of permissions a given account has. It also leads to inconsistency such as when two users that have the same job function end up with different assigned roles. When this gets multiplied across multiple applications and systems, it’s easy to see how quickly identity and access management can get out of hand.
A much bigger problem, however, is that these roles and permissions are typically assigned statically. Once they’re attached to a user’s account, they aren’t revoked. Over time, a user’s account accumulates more permissions (or roles) that are only used on occasion or never again. This results in risky over-provisioning.
Managing Access via Groups
One solution to tackling the sheer volume of identities, accounts, and permission sets is by utilizing groups. Groups are typically used one of two ways: as collections of users or collections of permissions.
When utilizing the user grouping approach, members are placed into a group based on shared identity attributes. For example, you may create a group for the marketing team and another for the engineering team. Group membership is then used to assign the right permissions (or roles) in the appropriate applications. All the developers on the engineering team would receive access to a different set of tools with different permissions from members of the marketing team (and the relative level of access for developers may be higher than what the marketing team gets on their tools).
One downside to assigning users to groups is broad group definition can make it so some members have more access than needed by other members. Creating more granular group definitions—such as separating out engineering into junior, senior, and team lead—can avoid the over provisioning at the expense of having many more groups to manage.
Alternatively, groups can be created as sets of permissions (or even set of roles). However, this approach also has drawbacks. When a group contains roles—or even other groups—this can abstract what the total scope of permissions available to group members actually is.
This can lead to situations where a child group is given additional roles or permissions which will now be inherited by the parent. In this case, it will not be obvious to group managers that any identity associated with the parent group now has more permissions than it may need to have. If access assigned across these groups is not regularly verified, teams can quickly lose track of who has access to what and where, especially as employees move positions or exit the company.
In the next blog post, we’ll dive further into the impacts of groups on access management, how traditional identity governance and administration (IGA) solutions handle these groups, and why they stumble in the cloud. If you're curious to learn more about access management built specifically for modern cloud, hybrid, and on-prem environments, reach out to the team for an in-depth demo.



Britive Team
View All PostsView All Posts


